[���ξW(w��ng)��(d��o)�x]���������ں�����ʯ�ć�����(zh��n)��һ��(zh��n)�����������˶���֪���@���C���˵����֡��F(xi��n)�ڣ�����������Ұ�ĸ����ˣ���ֻ�LJ��壬GOOGLE���ڽ̰��������ɰ����ՠtʯ���f�Ŀ��ƾ�����ʽ��ɴ��a�����@���C����������ƣ�
���������ں�����ʯ���������(zh��n)��һ��(zh��n)�����������˶���֪���@���C���������֡��F(xi��n)�ڣ�����������Ұ�ĸ����ˣ���ֻ�LJ��壬GOOGLE���ڽ̰��������ɰ������tʯ���f������������ʽ��ɴ��a�����@���C����������ƣ�

�ׂ�С�rǰ��Google Deepmind�����������ڽ�AlphaGo�����ՠtʯ���f�Ŀ��ƾ���������ɴ��a���Q����Ԓ�������@���C�������W(xu��)��(x��)������ƣ���һ�_ʼ����T�o��һ�����ƣ�ͨ�^�W(xu��)��(x��)GO���գ�Ȼ��oGOһ�����ƣ����Լ���ĥԓ����档�����Ǡtʯ��AlphaGOҲ�ڏ��f�����ЌW(xu��)��(x��)�������Ŀǰ�@���о��ܳ������кܶ��e�`��
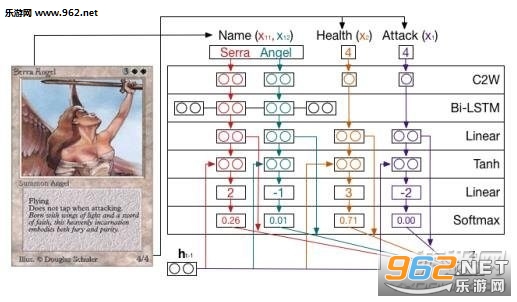
֮ǰ�I�ؽ�B�^google���о��tʯ���_�������䌍�����@���W(xu��)��(x��)ϵ�y(t��ng)��ǰ����ĿǰAlphaGO�ѽ�(j��ng)���10000���f���ƺ�500���tʯ��(sh��)��(j��)��Ŀǰ�W(xu��)����664���f�ǣ��tʯ66��������(sh��)���������S���ƣ���������@��������Ѫ����(bi��o)�R��Ȼ�������������_������

����һЩ���g(sh��)���棬AlphaGO߀�д���������ͬ���������������ͱ��^��(zh��n)�_�������řC���l(f��)�@�ӵ��Ƅt���g�����_��Ŀǰ��(zh��n)�_���f��61.4%���tʯ65.6%��Ŀǰ�о��T���^�m(x��)�C���W(xu��)��(x��)����ߜ�(zh��n)�_�ԡ�


 ϲ�g
ϲ�g  �
�  �o��
�o��  ���^
���^  ��
��  �y�^
�y�^ ��e�ӵ��C�� 2014�°���ٷ������Α�P�c
��e�ӵ��C�� 2014�°���ٷ������Α�P�c
 ���ڰ��I����4��25�յ��steam ��Ʒ�����淨�S��
���ڰ��I����4��25�յ��steam ��Ʒ�����淨�S��
 ����λһ�w���K�O�ϼ�������Ƭ���� �IJ���Ʒ���w
����λһ�w���K�O�ϼ�������Ƭ���� �IJ���Ʒ���w
 �����߂��f���o� ����Ҫ�� ���]GTX970�����@��
�����߂��f���o� ����Ҫ�� ���]GTX970�����@��
 ���������o�p8����������D(zhu��n)�N��ʾҕ�l
���������o�p8����������D(zhu��n)�N��ʾҕ�l
 �ƻ����������c���_�������w� �Α�r�L��8С�r
�ƻ����������c���_�������w� �Α�r�L��8С�r
 ���ؼ�Ħ�У�����66̖��·�A(y��)��Ƭ���� ����20���lِ��
���ؼ�Ħ�У�����66̖��·�A(y��)��Ƭ���� ����20���lِ��
 ���o(j��)Ԫ1800��ý�w�u�ֳ��t ����ϵ�����һ��
���o(j��)Ԫ1800��ý�w�u�ֳ��t ����ϵ�����һ��
���I(y��)���Α����d���C���T���W(w��ng)վ
Copyright 2009-2016 m.mmd178.cn ���(qu��n)����
��ICP��17018784̖-1