[���ξW(w��ng)���x]ai�O����ʲô��˼��һҹ֮�g��AI�O���ˡ����ȫ�W(w��ng)���ɴ����l(f��)�˴�Ҍ�ai���l�D(zhu��n)�Q���ߵ����P(gu��n)̽ӑ��ai�O������ʹ��GitHub�����һ���_Դ�ĿSO-VITS-SVC�����������Ñ������ڴ��Ŀ��ͨ�^ai���ܹ����ռ��O���˵���ɫ���Ķ�����Ŀ����ɫģ�́�������Ʒ��ai�O������ô���ģ���֪���������s�o��������
ai�O����ʲô��˼��һҹ֮�g��AI�O���ˡ����ȫ�W(w��ng)���ɴ����l(f��)�˴�Ҍ�ai���l�D(zhu��n)�Q���ߵ����P(gu��n)̽ӑ��ai�O������ʹ��GitHub�����һ���_Դ�ĿSO-VITS-SVC�����������Ñ������ڴ��Ŀ��ͨ�^ai���������ռ��O���˵���ɫ���Ķ�����Ŀ����ɫģ�́�������Ʒ��ai�O������ô���ģ���֪���������s�o��������

ai�O����ʲô��˼
һҹ֮�g��AI�O���ˡ����ȫ�W(w��ng)����Bվ�ϣ�AI�O���˷������ֿ��ܡ����f�����ܶ���������Ԫǰ�����w�ס��ɶ����ȵȣ�һ���W(w��ng)�����ݟo���Ρ��W(w��ng)�ѱ�ʾ�� ��һ����AI�O���ˣ�����ȥ��......
�@Щ������Ʒ����һ������so-vits-svc���_Դ�Ŀ���H�{��(sh��)�����l���Ϳ���һ������ʽģ�́��ϳ�Ŀ����ɫ�����l��Ӗ�����Ñ���Ҫ���Wģ�͡��@��ģ�Ϳ��Ա������ߺ����{(di��o)��Ҳ�����ò�ͬ���Z����������
ai�O�������d�����c�����d��


ai�O��������
����һ��
һ���ʂ乤��
Ӗ����(sh��)��(j��)���P(gu��n)�I��Խ����|(zh��)�������l��(sh��)��(j��)��Ч��Խ�ã����h���ٜʂ�һ��С�r���ϵ����l��
�@�����hʹ�� N �����@�� 8G ���ϡ�
�Ҍ��Ŀ����Ҫ�Ĵ��a�����������˳�����������Ҫ�������uՓ�^(q��)���Ի���ͨ�^�·�朽�(li��n)ϵ�ҡ�
��Ȼ��Ҳ����ֱ�����_Դ���aֱ�Ӳ��𣬵�ַ����
GitHub - svc-develop-team/so-vits-svc: SoftVC VITS Singing Voice Conversion
�����h(hu��n)�����b
1.���bpytorch��ȌW�����
��Ҫ���bpytorch,torchaudio,torchvision������
������֮ǰ����https://yunlord.blog.csdn.net/article/details/129812705?spm=1001.2014.3001.5502
2.���b���P(gu��n)��ه
���Կ������d���Ŀ�а����ɂ�requirements.txt����windows������
�M�뵽�Ŀ�У�ͨ�^promptݔ������ָ�
pip install -r requirements_win.txt
������(sh��)��(j��)̎��
Ӗ�����l��߀����Ҫ�A�y�������f�D(zhu��n)�Q�����l�����������ĸ����Q��Ԓ�f���l�в��ܰ��������������ࡢ���ȣ����ԟoՓ��Ӗ�����A�y������Ҫ����(sh��)��(j��)�M��̎����
1.��ȡ��
�҂�����ͨ�^UVR5 �@��ܛ�����F(xi��n)�����c�����x��
�� Windows �¿���ֱ��ʹ�á����_ܛ����������������

�\�м��ɷ��x���Ͱ��ࡣ
Ȼ���ٰ����������ã�ȥ������
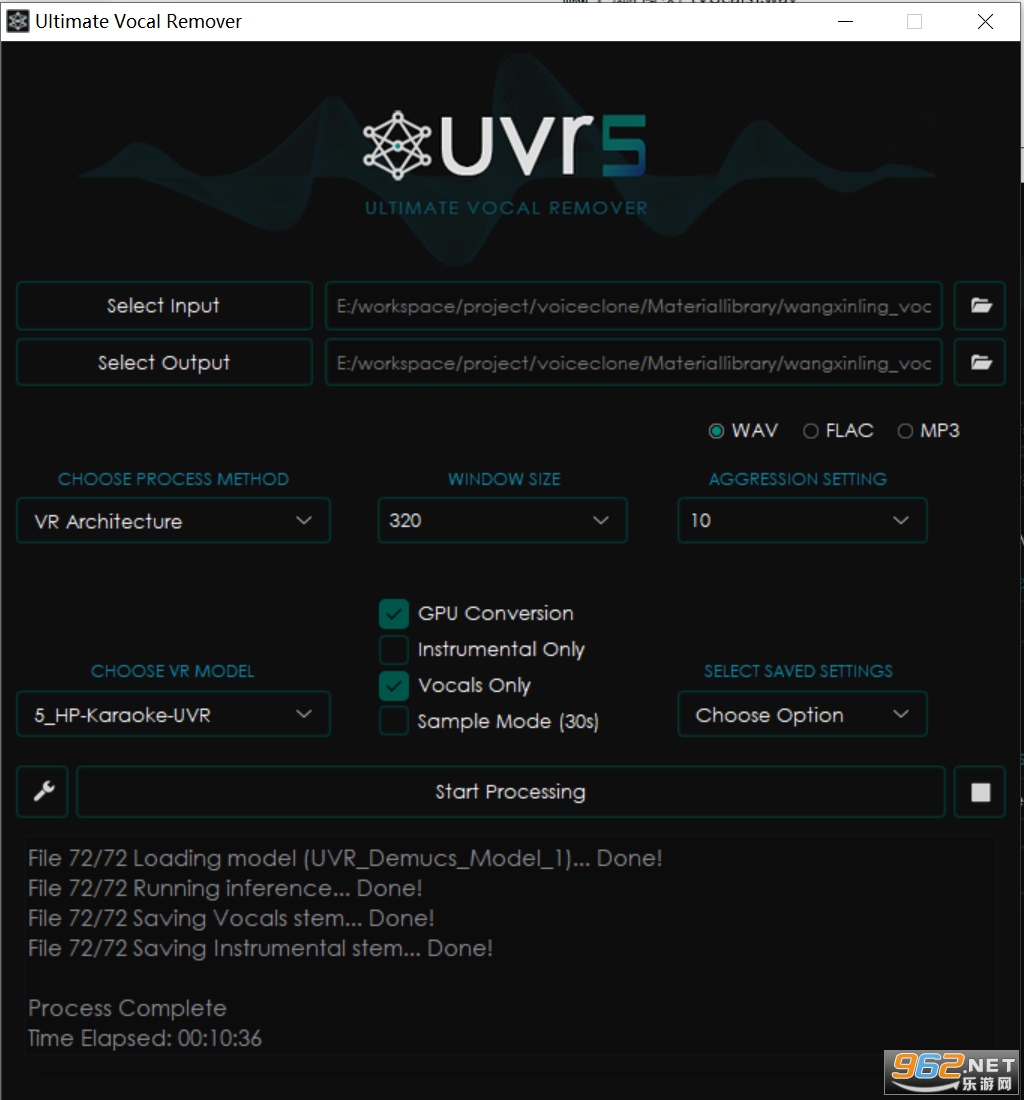
��(j��ng)�^��ȡ���ĸɃ������l�Ϳ����Á�Ӗ����
2.����l
���^������l̫�L����Ҫ���^��ʮ�룬�����ױ��@�棬��Ҫ�����l�ļ��M����Ƭ��
�҂�ͨ�^ Audio Slicer�@�����ߌ��F(xi��n)���l�з� ��
ֱ���\�� slicer-gui.exe��
�ݔ��·�����ݔ��·������������(sh��)��Ĭ�J���ɣ��@�Ӿ͕��õ��зֺõ����l�Ρ�

���h����֮����� �£���Ч�����õĄh�������|(zh��)�������l�Ȕ�(sh��)�����Ч�����á��������߀�Еr�L���^30s�Ŀ���ͨ�^����python���l�и���a�M�н��С�
���Ŀ�� so-vits-svc-4.0/dataset_raw Ŀ���(chu��ng)��һ���ļ��A�������ҵ��� wang_processed����̎���õĔ�(sh��)��(j��)�ŵ����档
�ġ�Ӗ��ģ��
��Ӗ��ģ��ǰ���҂���Ҫ�º�ԭʼģ�ͣ�������ŵ�����(y��ng)λ��
��checkpoint_best_legacy_500.pt����hubert�ļ��A��
��D_0.pth��G_0.pth����logs/44kĿ���
1.��(sh��)��(j��)�A̎��
��������ֱ���\���Ŀ�����1.��(sh��)��(j��)�A̎��.bat��
�@���_�����ǰ��ղ��E���\�и��� py �_��
�زɘ���44100Hz����
python resample.py
�Ԅӄ���Ӗ��������C�����Ԅ����������ļ�
python preprocess_flist_config.py
����hubert�cf0
python preprocess_hubert_f0.py
̎���ꮅ����� datset/44k ������һ���ļ��A������Ĕ�(sh��)��(j��)���D��ʾ
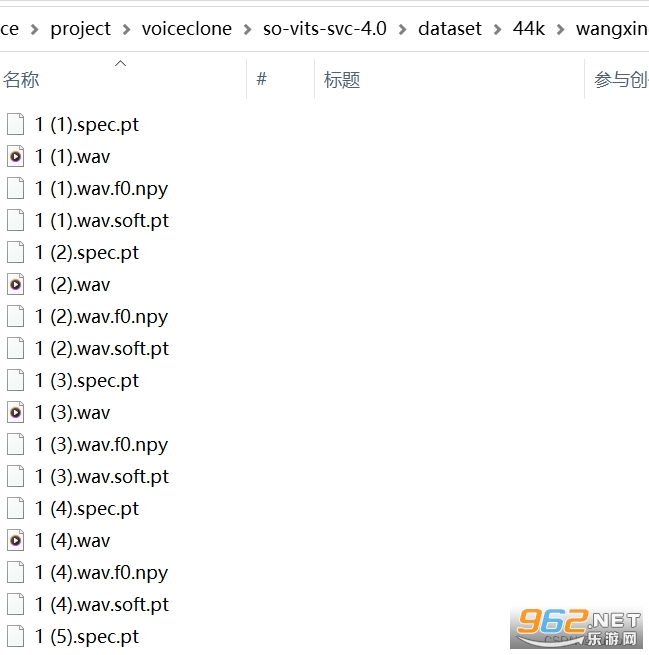
���Ԅh�� dataset_raw �ļ��A�ˡ�
2.ģ��Ӗ��
ֱ���\���Ŀ�е�2.Ӗ��.bat�����_��Ӗ����
python train.py -c configs/config.json -m 44k
����@����ÿ������� batch_size ���Ӗ���ٶȌ���(y��ng)�������ļ��� configs/config.json �ļ��
�@��Ӗ���r�g���L�������X�������(sh��)��(j��)�^�õ�Ԓ��Ӗ����30000݆���Ͼ���һ�����e��Ч����
3.���ģ��Ӗ��
ֱ���\���Ŀ�е�3.Ӗ�����ģ��.bat�����_��Ӗ�����@�����^�죬��犼������ꡣ
�@����Ҫ�ǿ��ԜpС��ɫй©��ʹ��ģ��Ӗ����������Ŀ�˵���ɫ�����䌍�����e���@�����džμ��ľ����������ģ�͵�ҧ�֣������X���壬�@�������@����ģ�Ͳ������ںϵķ�ʽ�����Ծ��Կ��ƾ�����c�Ǿ������ռ�ȣ�Ҳ���ǿ����ք�����Ŀ����ɫ��ҧ������֮�g�{(di��o)���������ҵ����m�������c��
ʹ�þ��ǰ������в��E�����M���κε�׃�ӣ�ֻ��Ҫ�~��Ӗ��һ�����ģ�ͣ��mȻЧ�����^���ޣ���Ӗ���ɱ�Ҳ���^�͡�
Ӗ���^�̣�
��(zh��)��python cluster/train_cluster.py��ģ�͵�ݔ������logs/44k/kmeans_10000.pt
�����^�̣�
inference_main.py��ָ��cluster_model_path
inference_main.py��ָ��cluster_infer_ratio��0����ȫ��ʹ�þ��1��ֻʹ�þ��ͨ���O(sh��)��0.5����
4.�����A�y
�ʂ��
�ʂ�һ��ĸ����������������l�زĜʂ��ǘ�̎����ͨ�^UVR5��ȡһ�β����^90s�ĸ��زġ�
��ģ����
�� app.py ����@һ��
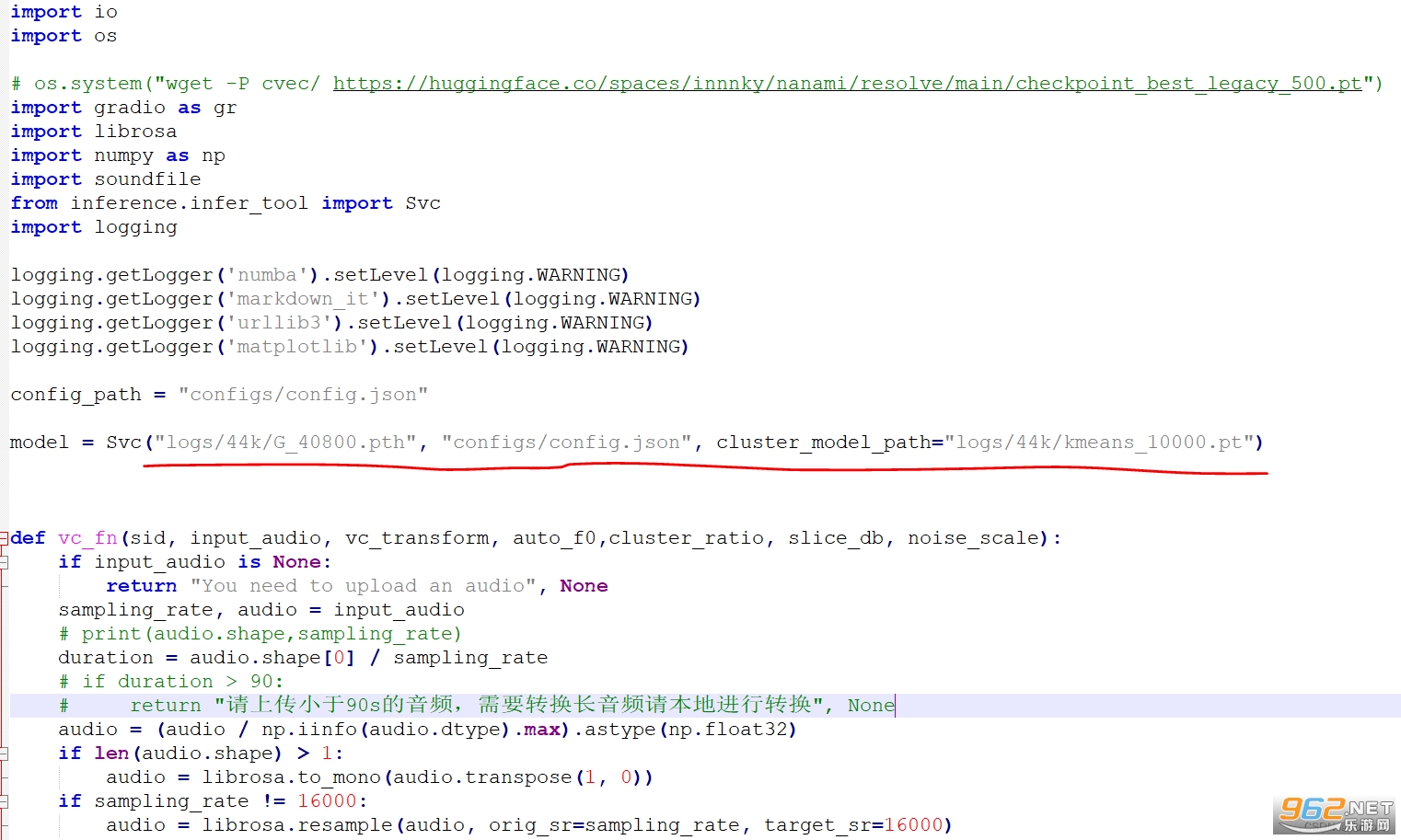
Ӗ���õ�ģ�ʹ������ logs/44k Ŀ����@��Ğ�Ӗ���õ�ģ�͵�ַ���Լ�����(y��ng)�������ļ�������ǵ��������ɵ� pt �ļ�·����
�\��web
ֱ���\���Ŀ�е�4.�����A�y.bat��
�����ֱ���_��һ�� webui�����_���� url��ֱ�ӏ��Ƶ��g�[����ַ���д��_���ɡ�
����һ�������� Web ��棬����ą���(sh��)������ֱ��ʹ��Ĭ�J�ģ�����һ�����l�������D(zhu��n)�Q��ɫ��
��������
���dGitHub app���������½̳��M�в���
GitHub���d�����c�����d��
github���Ժܷ�����҂����c�_Դ�Ŀ�У���ؕ�I�Լ��Ĵ��a.��ô,�҂���ôȥ���cһ���_Դ��github�Ŀ�أ�
���ȣ�ȥ�L����Ҫ���c��github��퓣��c����Fork�� => create Fork.

2. Ȼ���@�ӾͰ��@���Ŀ��ؐ��������h�̂}�죬�����Լ����~̖��䛲鿴��Ă}�죬���l(f��)�F(xi��n)��Ă}���ѽ�(j��ng)�����@���Ŀ���c��Code,copy���github��ַ��һ��Ҫע�⣬Ҫ���Լ���github�~̖���M�У���Ҫ���Ŀ���ߵĂ}���ϣ������ľ�Й�(qu��n)��,���Dz����M�����ͺ��ĵ�.


3.��D,��git����������git clone + copy��github��ַ�т}���¡����Ĺ����^(q��)��,
clone��ɺ���Ϳ�������Ĺ����^(q��)�����@���Ŀ�ļ���Ȼ����Ϳ����_ʼ�ɻ��ˣ�
�������Ȱ���Ĵ��a�ύ����Ă}������:
git add test.md;
gti commit -m something
git push origin���h�̂}�죬 -u master�����ط�֧��
עpush ���� -u ����(sh��) �Ǟ�������h�̂}���c��ı��ط�֧�����B�ӣ��Ժ�push�ĕr��Ϳ��Բ��ؼ����@������(sh��)��.
Ȼ��������~̖���M�� Pull requestsؕ�I��Ĵ��a��
���ڌ����Ƿ������Ĵ��a��Ҫ��������������

 ϲ�g
ϲ�g  �
�  �o��
�o��  ���^
���^  ��
��  �y�^
�y�^ airasia(com.airasia.mobile)app v12.6.0
�����н�ͨ / 24-05-24
airasia(com.airasia.mobile)app v12.6.0
�����н�ͨ / 24-05-24
 ��(y��u)Ѳai�ƱO(ji��n)��v1.3.2 �ٷ���
�����ù��� / 23-08-03
��(y��u)Ѳai�ƱO(ji��n)��v1.3.2 �ٷ���
�����ù��� / 23-08-03
 gencraft ai�L�� v1.1.1
�����ù��� / 23-05-08
gencraft ai�L�� v1.1.1
�����ù��� / 23-05-08
 늄ӻ�܇ģ�M��Electric Trains0.809�汾v0.809 ���°�
�����e���� / 24-05-17
늄ӻ�܇ģ�M��Electric Trains0.809�汾v0.809 ���°�
�����e���� / 24-05-17
 project sekai�_���� v3.6.0
�������赸 / 24-05-27
project sekai�_���� v3.6.0
�������赸 / 24-05-27
 cվ ai�L�����b v1.0.2.6
�����ù��� / 23-10-23
cվ ai�L�����b v1.0.2.6
�����ù��� / 23-10-23
���I(y��)���Α����d���C���T���W(w��ng)վ
Copyright 2009-2016 m.mmd178.cn ���(qu��n)����
��ICP��17018784̖-1

���T�uՓ
�����uՓ